What is Exploratory Data Analysis?
Exploratory Data Analysis (EDA) is an approach to analyzing data when you do not yet have a clear hypothesis or modeling goal.
Instead of jumping directly into modeling, EDA focuses on understanding the structure, patterns, and anomalies in the data.
EDA aims to:
- Maximize insight into the dataset
- Uncover underlying structure
- Identify important variables
- Detect outliers and anomalies
- Test assumptions for later modeling
- Develop simpler (parsimonious) models
- Generate hypotheses driven by data
EDA by Dimensionality
Low-dimensional data (1–3 dimensions):
- Summary statistics (mean, median, variance)
- Direct plotting (1D, 2D, 3D)
High-dimensional data:
- Visualization becomes difficult
- Dimensionality reduction techniques such as PCA are required
Data Visualization
Why Visualize Data?
Humans are exceptionally good at recognizing visual patterns.
Visualization leverages this ability to quickly detect trends, clusters, gaps, and anomalies that are hard to see in raw tables.
The limitation is scale: as the number of dimensions or data points grows, visualization becomes harder and requires careful design.
Four Primary Purposes of Visualization
- Composition: What parts make up the whole?
- Distribution: How are values spread?
- Comparison: How do values differ across groups?
- Relationship: How do variables relate to each other?
Data Summarization
Measures of Location
-
Mean:
- Median: Middle value (50% above, 50% below)
- Quartiles:
- Q1: 25% of data below
- Q3: 75% of data below
- Mode: Most frequent value

Measures of Dispersion
-
Variance:
-
Standard deviation:
- Range: max − min
- Interquartile range (IQR): Q3 − Q1


Skew
Skew describes where most of the data mass lies relative to the median.
- Negative skew: Long tail on the left, mass at higher values
- Positive skew: Long tail on the right, mass at lower values
Composition Visualization
Pie Charts
Pie charts show how discrete categories contribute to a whole.
They are best used when the number of categories is small and differences are large.
Stacked Bar Charts
Stacked bars are generally preferred over pie charts because they:
- Allow easier comparison across groups
- Show trends over time more clearly
Distribution Visualization
Histograms
Histograms visualize the distribution of a single continuous variable by dividing the range into bins and counting observations per bin.
They reveal:
- Center (mean/median)
- Spread
- Skew
- Outliers
- Multiple modes
Histogram Limitations
Histograms can be misleading for small datasets because the shape depends heavily on bin width.
Different bin choices can lead to very different interpretations.
Kernel Density Estimation (KDE)
KDE estimates a smooth probability density function by placing a kernel around each data point.

- Kernel K: Shape (Gaussian, uniform, etc.)
- Bandwidth h: Controls smoothness
Small 
Comparison Visualization
Bar Plots
Bar plots compare values across categories or models.
They are effective for showing differences in magnitude.
Box Plots
Box plots summarize a continuous variable across discrete groups.
- Center line: median
- Box: first to third quartile
- Whiskers: range (or 1.5×IQR)
- Points outside: outliers
Relationship Visualization
Scatter Plots
Scatter plots display relationships between two continuous variables.
They reveal:
- Presence or absence of relationships
- Linear vs non-linear trends
- Outliers
- Homoskedastic vs heteroskedastic behavior
Scatterplot Matrix
A scatterplot matrix shows pairwise relationships among many variables.
Each cell contains a scatter plot for one variable pair.
Overplotting and Jitter
When data points overlap heavily (common with integer data), patterns become hidden.
Jittering adds small random noise to reveal data density.
Dimensionality Reduction
Why Reduce Dimensionality?
- Simplifies modeling
- Reduces computational cost
- Removes redundancy
- Reveals hidden structure
Dimensions That Can Be Dropped
- Constant: no variation
- Nearly constant: minimal variation
- Linearly dependent: redundant information
Goals of Dimensionality Reduction
- High variance: preserve informative dimensions
- Low covariance: avoid redundant dimensions
Change of Basis
The most informative directions in data are often not aligned with the original axes.
Dimensionality reduction rotates the coordinate system to align with directions of maximum variance.
Principal Component Analysis (PCA)
PCA Overview
PCA transforms an 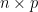
while preserving as much variance as possible.
PCA Steps
- Center data so each column has mean 0
- Compute covariance matrix
- Perform eigendecomposition:
- Use eigenvectors as new axes (principal components)


Key Mathematical Goal
Choose a transformation 


Dimensionality Reduction with PCA
Keeping only the first 

reduces dimensionality while retaining most variance.
Scree Plot
A scree plot shows eigenvalues versus component index.
The number of components is chosen where most variance is captured (often 80–90%).
PCA Applications
- Image compression
- Facial recognition (eigenfaces)
- Finance (market factors)
- High-dimensional visualization